正则表达式匹配中文实例
发布时间:2024-07-10 21:49
下面围绕“正则表达式匹配中文实例”主题解决网友的困惑
Python用正则表达式匹配含有中文的字符串,匹配不到?
coding=utf-8import res = u'首 页 'r = re.compile(u'(.*?)(?=)')ss = r.findall(s)for str in ss: print str运行结果:
如何用正则表达式匹配汉字?
一般情况下可以这样匹配中文,如图: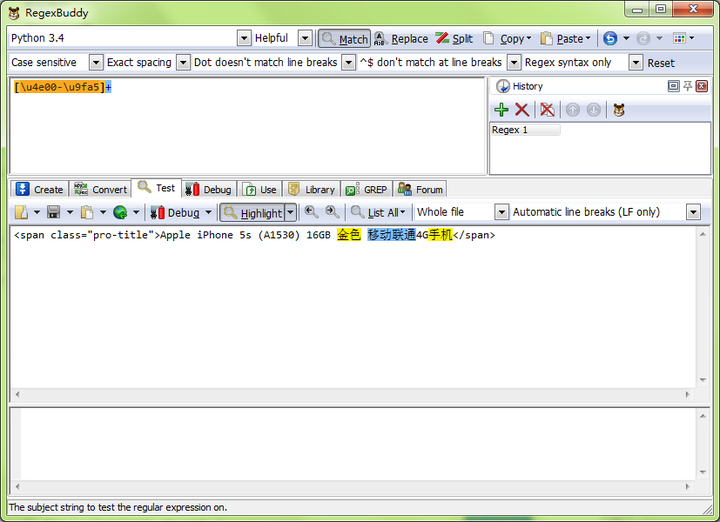
用JAVA语言编写正则表达式匹配指定的汉字的方法
"^[\\u4e00-\\u9fa5]+$"匹配全为中文,不能为空,要为空将+换成
EditPlus中的正则表达式中英文使用详解
EditPlus中的正则表达式中英文详解(附常用实例) /t Tab character.tab符号 /n New line.新的一行(换行符) . Matches any character.任何字符 | Either expression ...
怎么用正则表达式匹配下面的一行汉字
正则表达式 (.+?)<\/span> 取第一捕获组的数据 我给你一个Javascript语言的例子你看看吧 var str='上隐水产海鲜自助餐厅';var regex=/(.+?)<\/span>/ig;var resul...
正则表达式 匹配中文 [一,二,三,四,五]一次或多次但
建议结合其他编程语言实现,例如使用python:s = "一二三四四"result = re.findall("\w",s)print(set(result))使用\w可找到每一个字符,进而形成列表结果,使用set...
php 正则表达式匹配 取得中文,如:中心东路 ;取得坐
1: 0,(-2639.848633,-2544.598145; 268,0,1; -1,-1) 21262460312,21262402701 4,-1 >1, 7.666504 >3942, 32.685303 >8744, 14.188477 >9265, 0.640869";pa = "{...
要求正则表达式匹配汉字,但不匹配“除”“停”这两
正则表达式 ^((?!除|停)[\u4e00-\u9fa5])+ 我给你一个Java语言的例子,你看看吧 import java.util.regex.Matcher;import java.util.regex.Pattern;public class AA ...
网站已经找到数个正则表达式匹配中文实例的检索结果
更多有用的内容,可前往偷笑网主页查看
| 其他小伙伴的相似问题3 | ||
|---|---|---|
| 非中文的正则表达式 | 正则表达式精确匹配 | 正则表达式匹配汉字 |
| js正则表达式匹配字符串 | 中文正则表达式 | 正则表达式匹配指定字符串 |
| 不适定问题的正则化方法 | 正则表达式匹配数字 | 正则表达式不包含中文 |
| 正则表达式怎么用 | 返回首页 | |
| 返回顶部 |
©CopyRight 2011-2024
1.本站为非盈利站点,旨在为网友提供一些知识点,内容仅供参考。如发现数据错误或观点错误,还请海涵并指正,我会提升算法纠错能力,以提供更加真实正确的资讯。
2.文字图片均来源于网络。如侵犯您的版权或隐私,请联系rscp888@gmail.com说明详情,我们会及时删除。
——偷笑网